Introduction
Hello, this is swim-lover. I’m trying object detection by Pytourch. I’ve just started Python, and I’m studying with the concept of “learning while using”. I learned about the DataLoader function that appeared in the preparation of MNIST data using Pytorch. I would like to continue studying Python, but as a separate part, I would like to start object detection by Pytorch.
SSD Single Shot Multibox Detector
When I searched for the keywords Pytorch and object detection, I found many examples of using SSD (Single Shot Multibox Detector) and YOLO (you only look once). This time, I would like to touch on SSD. The SSD paper has the following figure.

It was written on the SSD that (a) input images and Ground truth boxes are required during learning. Ground truth seems to mean correct answer data, but Box of correct answer data does not come in easily. Here, I understand in advance that you should make a rectangle surrounding the object (cat, dog) and a mark that is a dog or cat. Then it seems to proceed with different scales (b) 8×8 and (c) 4,4 maps using a small set of several boxes (default boxes in the example). And in each Box, for all object categories (dog, cat, car, etc.), offset delta (cx, cy, w, h) with the target object, reliability confidence (c1 = 10%, c2 = 80%) , C3 = 0.1%) seems to be calculated. When learning, it seems to match the default box with the Ground truth boxes.
A diagram of the detection model was also included in the paper. The output seems to be 8732 outputs for each class. (Detections: 8732 per classes), and Non-Maximum Suppression processing is performed at the final stage. It seems that the output is decimated from 8732 outputs.

Even if I dig deeper into the dissertation than this, it will exceed my understanding, so I would like to actually use SSD.
Object detection using trained data
I think most of the first steps in using SSDs with Pytorch are to use trained data. Also, the sample code of Pytorch is also released, so I decided to use it as it is. Since the code of colab is published as it is on the Pytorch site, copy it to your Colab environment as it is and execute it.
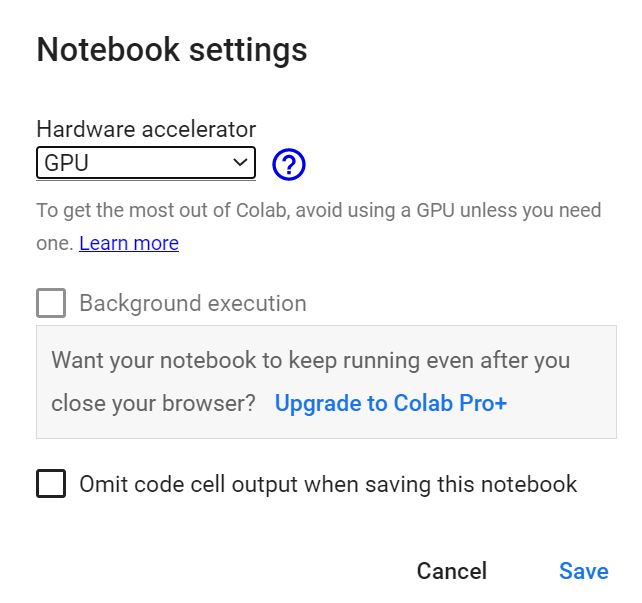
There is one caveat. If colab’s runtime type setting (select Runtime-> Change Runtime Type from the menu) doesn’t seem to be GPU, you need to set it to GPU.
Python code and execution results
import torch
print(torch.__version__)
precision = 'fp32'
device = torch.device('cpu')
#print(torch.cuda.is_available())
#torch.hub.list('NVIDIA/DeepLearningExamples:torchhub')
#torch.hub.help('NVIDIA/DeepLearningExamples:torchhub','nvidia_ssd')
ssd_model = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd', model_math=precision)#trained model
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd_processing_utils')#processing utility
# change cpu mode , evaluation mode
ssd_model.to('cpu')
ssd_model.eval()
#input data
uris = [
'http://images.cocodataset.org/val2017/000000397133.jpg',
'http://images.cocodataset.org/val2017/000000037777.jpg',
'http://images.cocodataset.org/val2017/000000252219.jpg'
]
# make input data
inputs = [utils.prepare_input(uri) for uri in uris]
tensor = utils.prepare_tensor(inputs, precision == 'fp16')
tensor = tensor.to('cpu')
# deteection
with torch.no_grad():
detections_batch = ssd_model(tensor)
# detection type and number
classes_to_labels = utils.get_coco_object_dictionary()
print(classes_to_labels)
print('class num', len(classes_to_labels))
# result
results_per_input = utils.decode_results(detections_batch)
best_results_per_input = [utils.pick_best(results, 0.40) for results in results_per_input]
# 1st result
bboxes, classes, confidences = best_results_per_input[0]
print('box', bboxes)
print('class', classes, classes_to_labels[classes[0]-1])
print('confidence', confidences)
from matplotlib import pyplot as plt
import matplotlib.patches as patches
for image_idx in range(len(best_results_per_input)):
fig, ax = plt.subplots(1)
# Show original, denormalized image...
image = inputs[image_idx] / 2 + 0.5
ax.imshow(image)
# ...with detections
bboxes, classes, confidences = best_results_per_input[image_idx]
for idx in range(len(bboxes)):
left, bot, right, top = bboxes[idx]
x, y, w, h = [val * 300 for val in [left, bot, right - left, top - bot]]
rect = patches.Rectangle((x, y), w, h, linewidth=1, edgecolor='r', facecolor='none')
ax.add_patch(rect)
ax.text(x, y, "{} {:.0f}%".format(classes_to_labels[classes[idx] - 1], confidences[idx]*100), bbox=dict(facecolor='white', alpha=0.5))
plt.show()

Conclution
This time, I tried object recognition using Mobile Net. I just moved the sample as it is. From the next time onward, I would like to try using my own videos to see if it can be detected.

I’m an embedded software engineer. I have avoided front-end technology so far, but I started studying to acquire technology in a different field.
My hobbies are swimming, road bike, running and mountaineering.
We will send out information about embedded technology, front-end technology that we have studied, and occasional hobby exercises.


コメント